

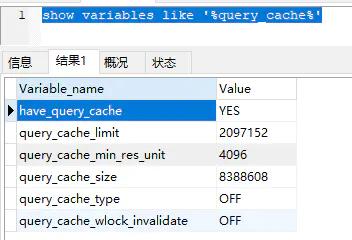
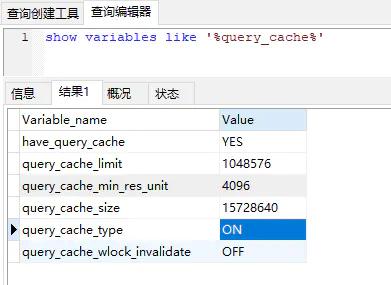
1、選擇最合適的字段屬性
Mysql是一種關(guān)系型數(shù)據(jù)庫,可以很好地支持大數(shù)據(jù)量的存儲,但是一般來說,數(shù)據(jù)庫中的表越小,在它上面執(zhí)行的查詢也就越快。因此,在創(chuàng)建表的時候,為了獲得更好的性能,我們可以將表中字段的寬度舍得盡可能小。
例如:在定義郵政編碼這個字段時,如果將其設(shè)置為char(255),顯然給數(shù)據(jù)庫增加了不必要的空間,甚至使用這種類型也是多余的,因為char(6)就可以很好地完成了任務(wù)。同樣的如果可以的話,我們應(yīng)該是用而不是來定義整形字段。
推薦下自己做的 Boot 的實戰(zhàn)項目:
2、盡量把字段設(shè)置為NOT NULL
在可能的情況下,盡量把字段設(shè)置為NOT NULL,這樣在將來執(zhí)行查詢的時候,數(shù)據(jù)庫不用去比較NULL值。
對于某些文本字段來說,例如“省份”或者“性別”,我們可以將他們定義為ENUM(枚舉)類型。因為在MySQL中,ENUM類型被當(dāng)做數(shù)值型數(shù)據(jù)來處理,而數(shù)值型數(shù)據(jù)被處理起來的速度要比文本類型要快得多。這樣我們又可以提高數(shù)據(jù)庫的性能。
推薦下自己做的 Cloud 的實戰(zhàn)項目:
3、使用連接(JOIN)來代替子查詢(Sub-)
MySQL從4.1開始支持SQL的子查詢。這個技術(shù)可以使用語句來創(chuàng)建一個單例的查詢結(jié)果,然后把這個結(jié)果作為過濾條件用在另一個查詢中。
例如:我們要將客戶基本信息表中沒有任何訂單的客戶刪除掉,就可以利用子查詢先從銷售信息表中將所有發(fā)出訂單的客戶id取出來,然后將結(jié)果傳遞給主查詢,如下圖所示:
如果使用連接(JOIN)來完成這個工作,速度將會快很多,尤其是當(dāng)表中對建有索引的話,性能將會更好,查詢?nèi)缦拢?/p>
連接(JOIN)之所以更有效率一些,是因為MySQL不需要在內(nèi)存中創(chuàng)建臨時表來完成這個邏輯上 需要兩個步驟的查詢工作。
另外,如果你的應(yīng)用程序有很多JOIN查詢,你應(yīng)該確認兩個表中JOIN的字段是被建立過索引的。這樣MySQL內(nèi)部 會啟動為你優(yōu)化JOIN的SQL語句的機制。而且這些被用來JOIN的字段,應(yīng)該是相同的類型的。
例如:如果你要把字段和一個INT字段JOIN在一起,MySQL就無法使用他們的索引。對于那些類型,還需要有相同的字符集才行。(兩個表的字符集可能不相同)。
inner join內(nèi)連接也叫做等值連接,left/right join是外鏈接。
SELECT?A.id,A.name,B.id,B.name?FROM?A?LEFT?JOIN?B?ON?A.id=B.id;
SELECT?A.id,A.name,B.id,B.name?FROM?A?RIGHT?JOIN?ON?B?A.id=?B.id;
SELECT?A.id,A.name,B.id,B.name?FROM?A?INNER?JOIN?ON?A.id?=B.id;
經(jīng)過多方面的證實inner join性能比較快,因為inner join是等值連接,或許返回的行數(shù)比較少。但是我們要記得有些語句隱形的用到了等值連接,如:
SELECT?A.id,A.name,B.id,B.name?FROM?A,B?WHERE?A.id?=?B.id;
sql中的連接查詢有inner join(內(nèi)連接)、left join(左連接)、right join(右連接)、full join(全連接)四種方式,它們之間其實并沒有太大區(qū)別,僅僅是查詢出來的結(jié)果有所不同。
例如我們有兩張表:
表通過外鍵Id_P和表進行關(guān)聯(lián)。
inner join(內(nèi)連接),在兩張表進行連接查詢時,只保留兩張表中完全匹配的結(jié)果集。
我們使用inner join對兩張表進行連接查詢,sql如下:
SELECT?p.LastName,?p.FirstName,?o.OrderNo
FROM?Persons?p
INNER?JOIN?Orders?o
ON?p.Id_P=o.Id_P?and?1=1??--用and連接多個條件

ORDER?BY?p.LastName
查詢結(jié)果集:
此種連接方式表中Id_P字段在表中找不到匹配的,則不會列出來。
注意:單純的 * from a,b是笛卡爾乘積。比如a表有5條數(shù)據(jù),b表有3條數(shù)據(jù),那么最后的結(jié)果有5*3=15條數(shù)據(jù)。
但是如果對兩個表進行關(guān)聯(lián): * from a,b where a.id = b.id意思就變了,此時就等價于:
select?*?from?a?inner?join?b?on?a.id = b.id。?--?即就是內(nèi)連接。
但是這種寫法并不符合規(guī)范,可能只對某些數(shù)據(jù)庫管用,如。推薦最好不要這樣寫。最好寫成inner join的寫法。
內(nèi)連接查詢 ( * from a join b on a.id = b.id) 與 關(guān)聯(lián)查詢 ( * from a , b where a.id = b.id)的區(qū)別
left join,在兩張表進行連接查詢時,會返回左表所有的行,即使在右表中沒有匹配的記錄。
我們使用left join對兩張表進行連接查詢,sql如下:
SELECT?p.LastName,?p.FirstName,?o.OrderNo
FROM?Persons?p
LEFT?JOIN?Orders?o
ON?p.Id_P=o.Id_P
ORDER?BY?p.LastName
查詢結(jié)果如下:
可以看到,左表(表)中為Bush的行的Id_P字段在右表(表)中沒有匹配,但查詢結(jié)果仍然保留該行。
right join,在兩張表進行連接查詢時,會返回右表所有的行,即使在左表中沒有匹配的記錄。
我們使用right join對兩張表進行連接查詢,sql如下:
SELECT?p.LastName,?p.FirstName,?o.OrderNo
FROM?Persons?p
RIGHT?JOIN?Orders?o
ON?p.Id_P=o.Id_P
ORDER?BY?p.LastName
查詢結(jié)果如下:
表中最后一條記錄Id_P字段值為65,在左表中沒有記錄與之匹配,但依然保留。
full join,在兩張表進行連接查詢時,返回左表和右表中所有沒有匹配的行。
我們使用full join對兩張表進行連接查詢,sql如下:
SELECT?p.LastName,?p.FirstName,?o.OrderNo
FROM?Persons?p
FULL?JOIN?Orders?o
ON?p.Id_P=o.Id_P
ORDER?BY?p.LastName
查詢結(jié)果如下:
查詢結(jié)果是left join和right join的并集。
4、使用聯(lián)合(UNION)來代替手動創(chuàng)建的臨時表
MySQL從4.0版本開始支持union查詢,他可以把需要使用臨時表的兩條或更多的查詢合在一個查詢中。在客戶端查詢會話結(jié)束的時候,臨時表會被自動刪除,從而保證數(shù)據(jù)庫整齊、高效。使用union來創(chuàng)建查詢的時候,我們只需要用union作為關(guān)鍵字把多個語句連接起來就可以了,要注意的是所有語句中的字段數(shù)目要相同。
下面一個例子就演示了一個使用union額查詢。
當(dāng)我們可以確認不可能出現(xiàn)重復(fù)結(jié)果集或者不在乎重復(fù)結(jié)果集的時候盡量使用union all而不是union,因為union和union all的差異主要是前者需要將兩個或者多個結(jié)果集合并后再進行唯一性過濾操作,這就會涉及到排序,增加大量的CPU運算,增大資源消耗及延遲。
5、事務(wù)
盡管我們可以使用子查詢(Sub-)、連接(JOIN)和聯(lián)合(UNION)來創(chuàng)建各種各樣的查詢,但不是所有的數(shù)據(jù)庫操作,都可以只用一條或少數(shù)幾條就可以完成的。更多的時候是需要用一系列的語句來完成某種工作。但是在這種情況下sql 子查詢 左連接,當(dāng)這個語句塊中的某一條語句運行出錯的時候,整個語句塊的操作就會變得不確定起來。
設(shè)想一下,要把某個數(shù)據(jù)同時插入兩個相關(guān)聯(lián)的表中,可能會出現(xiàn)這樣的情況:第一個表中成功更新后,數(shù)據(jù)庫突然出現(xiàn)意外狀況,造成第二個表中的操作沒有完成,這樣就會造成數(shù)據(jù)的不完整,甚至?xí)茐臄?shù)據(jù)庫中的數(shù)據(jù)。要避免這種情況,就應(yīng)該使用事務(wù),它的作用是要么語句塊中每條語句都操作成功,要么都失敗。
換句話說,就是可以保持數(shù)據(jù)庫中的數(shù)據(jù)的一致性和完整性。事務(wù)以BEGIN關(guān)鍵字開始,關(guān)鍵字結(jié)束。在這之間的一條SQL語句操作失敗,那么命令就可以把數(shù)據(jù)庫恢復(fù)到begin開始之前的狀態(tài)。
BEGIN;?
INSERTINTOsalesinfoSETCustomerID=14;
UPDATEinventorySETQuantity=11WHEREitem='book';
COMMIT;
事務(wù)的另一個作用是當(dāng)多個用戶同時使用相同的數(shù)據(jù)源時,他可以使用鎖定數(shù)據(jù)庫的方式來為用戶提供一種安全的訪問機制,這樣可以保證用戶的操作不被其它的用戶所干擾。
一般來說,事務(wù)必須滿足四個條件(ACID):原子性(,或稱不可分割性)、一致性()、隔離性(,又稱獨立性)、持久性().
事務(wù)的并發(fā)問題:
1、臟讀:事務(wù)A讀取了事務(wù)B更新的數(shù)據(jù),然后B回滾操作,那么A讀取到的數(shù)據(jù)就是臟數(shù)據(jù)
2、不可重復(fù)讀:事務(wù)A多次讀取同一事物,事務(wù)B在事務(wù)A多次讀取的過程中,對數(shù)據(jù)做了更新并提交,導(dǎo)致事務(wù)A多次讀取同一數(shù)據(jù)時,結(jié)果不一致。
3、幻讀:系統(tǒng)管理員A將數(shù)據(jù)庫中的所有學(xué)生的成績從具體分數(shù)改為ABCDE等級,但是系統(tǒng)管理員B就在這個時候插入了一條具體分數(shù)的記錄,當(dāng)系統(tǒng)管理員A改結(jié)束后發(fā)現(xiàn)還有一條記錄沒有改過來,就好像發(fā)生了幻覺一樣,這就叫幻讀。
小結(jié):不可重復(fù)讀的和幻讀很容易混淆,不可重復(fù)讀側(cè)重于修改,幻讀側(cè)重于新增或刪除。解決不可重復(fù)讀的問題只需鎖住滿足條件的行,解決幻讀需要鎖表
MySQL事務(wù)隔離級別:
事務(wù)隔離級別 臟讀 不可重復(fù)讀 幻讀
讀未提交(read-)

是
是
是
不可重復(fù)讀(read-)
否
是
是
可重復(fù)讀(-read)
否
否
是
串行化()
否
否
否
事務(wù)控制語句:
6、使用外鍵
鎖定表的方法可以維護數(shù)據(jù)的完整性,但是他卻不能保證數(shù)據(jù)的關(guān)聯(lián)性。這個時候我們可以使用外鍵。例如:外鍵可以保證每一條銷售記錄都指向某一個存在的客戶。
在這里,外鍵可以把表中的映射到表中,任何一條沒有辦法合法的記錄都不會被跟新或插入到中.
CREATE?TABLE?customerinfo(customerid?int?primary?key)?engine?=?innodb;
CREATE??TABLE???salesinfo(?salesid?int?not?null,customerid??int?not?null,?primary?key(customerid,salesid),foreign?key(customerid)??references??customerinfo(customerid)?on?delete?cascade)engine?=?innodb;
注意例子中的參數(shù)“on ”.該參數(shù)保證當(dāng)表中的一條客戶記錄也會被自動刪除。如果要在mysql中使用外鍵,一定要記住在創(chuàng)建表的時候?qū)⒈淼念愋投x為事務(wù)安全表類型。該類型不是mysql表的默認類型。定義的方法是在 TABLE語句中加上=。
7、鎖定表
盡管事務(wù)是維護數(shù)據(jù)庫完整性的一個非常好的方法,但卻因為他的獨占性,有時會影響數(shù)據(jù)庫的性能,尤其是很大的應(yīng)用系統(tǒng)中。由于在事務(wù)執(zhí)行的過程中,數(shù)據(jù)庫將會被鎖定,因此其他的用戶請求只能暫時等待直到該事務(wù)結(jié)束。
如果一個數(shù)據(jù)庫系統(tǒng)只有少數(shù)幾個用戶來使用,事務(wù)造成的影響不會成為太大的問題;但假設(shè)有成千上萬的用戶同時訪問一個數(shù)據(jù)庫系統(tǒng),例如訪問一個電子商務(wù)網(wǎng)站,就會產(chǎn)生比較嚴重的響應(yīng)延遲。
其實,有些情況下我們可以通過鎖定表的方式來獲得更好的性能。下面的例子就是鎖定表的方法來完成前面一個例子中事務(wù)的功能。
這里,我們用一個語句取出初始數(shù)據(jù),通過一些計算,用語句將新值更新到表中。包含有WRITE關(guān)鍵字的語句可以保證在命令被執(zhí)行之前,不會有其他訪問來對進行插入、更新或者刪除的操作。
8、使用索引
索引是提高數(shù)據(jù)庫性能的常用方法,他可以令數(shù)據(jù)庫服務(wù)器比沒有索引快得多的速度檢索特定的行,尤其是在查詢語句當(dāng)中包含有MAX(),MIN()和這些命令的時候,性能提高更為明顯。
那該對那些字段進行索引呢?
一般來說,索引應(yīng)該建立在那些將用于join,where判斷和排序的字段上。盡量不要對數(shù)據(jù)庫中某個含有大量重復(fù)的值的字段建立索引,對于一個ENUM類型的字段來說,出現(xiàn)大量重復(fù)值是很有可能的情況。
例如中的“”..字段,在這樣的字段上建立索引將不會有什么幫助;相反,還有可能降低數(shù)據(jù)庫的性能。我們在創(chuàng)建表的時候可以同時創(chuàng)建合適的索引,也可以使用或在以后創(chuàng)建索引。

此外sql 子查詢 左連接,MySQL從版本3.23.23開始支持全文索引和搜索。全文索引在MySQL中是一個類型索引,但僅能用于類型的表。對于一個大的數(shù)據(jù)庫,將數(shù)據(jù)裝載到一個沒有索引的表中,然后再使用或創(chuàng)建索引,將是非常快的。但如果將數(shù)據(jù)裝載到一個已經(jīng)有索引的表中,執(zhí)行過程將會非常慢。
9、優(yōu)化de的查詢語句
1 不使用子查詢
例: * FROM t1 WHERE id ( id FROM t2 WHERE name=’’);
子查詢在.5版本里,內(nèi)部執(zhí)行計劃器是這樣執(zhí)行的:先查外表再匹配內(nèi)表,而不是先查內(nèi)表t2,當(dāng)外表的數(shù)據(jù)很大時,查詢速度會非常慢。
在/.6版本里,采用join關(guān)聯(lián)方式對其進行了優(yōu)化,這條SQL會自動轉(zhuǎn)換為
SELECT?t1.*?FROM?t1?JOIN?t2?ON?t1.id?=?t2.id;
但請注意的是:優(yōu)化只針對有效,對/子查詢無效,固生產(chǎn)環(huán)境應(yīng)避免使用子查詢
2 避免函數(shù)索引
例:
SELECT?*?FROM?t?WHERE?YEAR(d)?>=?2016;
由于MySQL不像那樣支持函數(shù)索引,即使d字段有索引,也會直接全表掃描。
應(yīng)改為—–>
SELECT?*?FROM?t?WHERE?d?>=?‘2016-01-01’;
3 用IN來替換OR
低效查詢
SELECT?*?FROM?t?WHERE?LOC_ID?=?10&nbs***bsp;LOC_ID?=?20&nbs***bsp;LOC_ID?=?30;
—–> 高效查詢
SELECT?*?FROM?t?WHERE?LOC_IN?IN?(10,20,30);
4 LIKE雙百分號無法使用到索引
SELECT?*?FROM?t?WHERE?name?LIKE?‘%de%’;
—–>
SELECT?*?FROM?t?WHERE?name?LIKE?‘de%’;
目前只有.7支持全文索引(支持中文)
5 讀取適當(dāng)?shù)挠涗汱IMIT M,N
SELECT?*?FROM?t?WHERE?1;
—–>
SELECT?*?FROM?t?WHERE?1?LIMIT?10;
6 避免數(shù)據(jù)類型不一致
SELECT?*?FROM?t?WHERE?id?=?’19’;
—–>
SELECT?*?FROM?t?WHERE?id?=?19;
7 分組統(tǒng)計可以禁止排序
SELECT?goods_id,count(*)?FROM?t?GROUP?BY?goods_id;
默認情況下,MySQL對所有GROUP BY col1,col2…的字段進行排序。如果查詢包括GROUP BY,想要避免排序結(jié)果的消耗,則可以指定ORDER BY NULL禁止排序。另外,MySQL 系列面試題和答案全部整理好了,微信搜索Java技術(shù)棧,在后臺發(fā)送:面試,可以在線閱讀。
—–>
SELECT?goods_id,count(*)?FROM?t?GROUP?BY?goods_id?ORDER?BY?NULL;
8 避免隨機取記錄
SELECT?*?FROM?t1?WHERE?1=1?ORDER?BY?RAND()?LIMIT?4;
MySQL不支持函數(shù)索引,會導(dǎo)致全表掃描 —–>
SELECT?*?FROM?t1?WHERE?id?>=?CEIL(RAND()*1000)?LIMIT?4;
9 禁止不必要的ORDER BY排序
SELECT?count(1)?FROM?user?u?LEFT?JOIN?user_info?i?ON?u.id?=?i.user_id?WHERE?1?=?1?ORDER?BY?u.create_time?DESC;
—–>
SELECT?count(1)?FROM?user?u?LEFT?JOIN?user_info?i?ON?u.id?=?i.user_id;
10 批量插入
INSERT?INTO?t?(id,?name)?VALUES(1,’Bea’);
INSERT?INTO?t?(id,?name)?VALUES(2,’Belle’);
INSERT?INTO?t?(id,?name)?VALUES(3,’Bernice’);
—–>
INSERT?INTO?t?(id,?name)?VALUES(1,’Bea’),?(2,’Belle’),(3,’Bernice’);